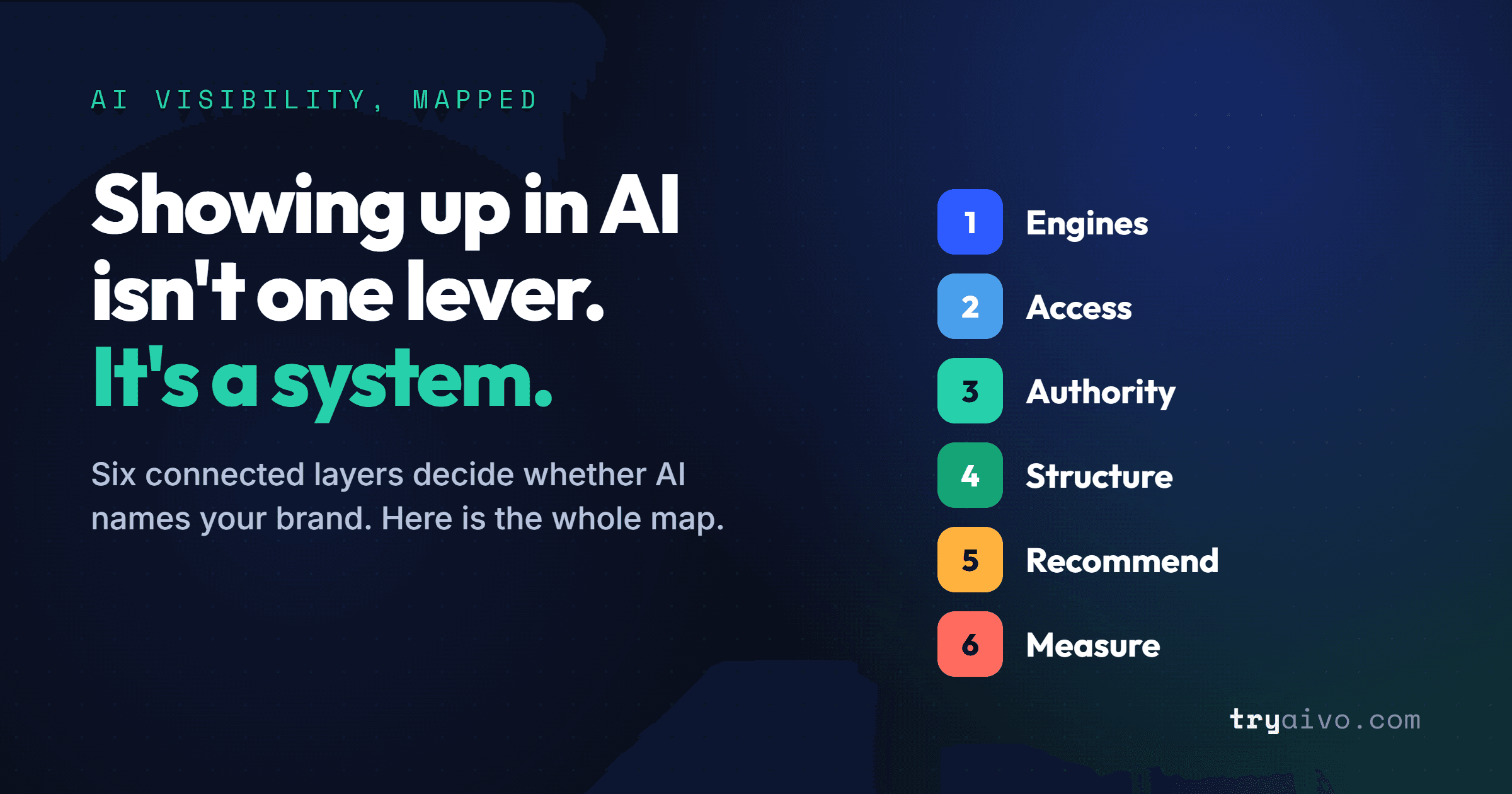
The AI Visibility Funnel: What Content Gets Cited
There is no single AI visibility playbook. We mapped ~700K AI citations across ChatGPT, Google, Perplexity, Gemini and Claude to show what content earns a mention, by platform and funnel stage.

The AI Visibility Funnel: What Content Gets Cited, by Platform and Funnel Stage
Most "how to show up in AI" advice is a single checklist. The data says that's wrong.
We mapped roughly 700,000 AI citations (US, English, unbranded discovery queries) from our client and research data across multiple industries and across ChatGPT, Google AI, Perplexity, Gemini and Claude to see what content actually earns a mention, and where. The answer is not one playbook. It's a grid: each platform reads a different web, and the priority shifts as a buyer moves from awareness to decision.
This is a starting place, not the final word. The grid below orients you. Your industry then reorders it, sometimes dramatically. We will show you exactly where.
📋 TL;DR (Key Takeaways)
- AI visibility has no single playbook. What gets cited changes by platform and by funnel stage.
- Engines split into two camps. Google AI (~~14.8 sources per answer) and Perplexity (~~8) are retrieval-heavy: being cited in many places wins. ChatGPT (~3.3) and Claude lean on training/parametric memory: being the well-known, consistently described entity wins.
- The funnel shifts the work. Awareness rewards how-to and explainers; consideration rewards best-of lists, comparisons and community; decision rewards reviews, pricing clarity and trade press.
- Industry changes everything. In SaaS, review platforms (G2, Capterra, Gartner) become the #1 decision lever. In e-commerce, Reddit and YouTube beat review sites.
- Use it as a baseline. Orient with the grid, then pressure-test against your own category and citation data.
Two structural truths the grid is built on
Before the grid, two findings explain why one checklist can't work.
1. Retrieval-heavy vs. parametric engines
AI assistants do not all build answers the same way.
- Google AI and Perplexity are retrieval-heavy. They pull a lot of sources per answer (Google AI cites ~14.8, Perplexity ~8.1 in our data). They assemble the answer from whatever is retrievable right now, so being cited in many places wins: YouTube, Reddit, roundups, reviews, trade press.
- ChatGPT and Claude lean on parametric/training memory. They cite far fewer sources (ChatGPT ~3.3) and answer more from what the model already "knows." You don't win those by chasing citations. You win by being the well-known, consistently described entity: a clean Wikipedia presence, earned press, and a category story that shows up the same way everywhere.
- Gemini sits in between (~5.3 sources) but is the most likely to actually recommend a brand once it surfaces one.
2. The priority shifts down the funnel
Across all engines, the mix of what gets cited moves as intent deepens:
- Awareness (top): first-party explainers, how-to video, and reference (Wikipedia) lead.
- Consideration (middle): best-of lists, "X vs Y" comparisons, community threads, and creator video rise.
- Decision (bottom): reviews, pricing clarity, and trade/industry press peak.
The AI visibility funnel (at a glance)
The top move per platform per stage. The full set of moves is in the platform-by-platform notes below. "Your site" means owned-and-operated pages.
| Platform | Awareness (Top) | Consideration (Middle) | Decision (Bottom) |
| ChatGPT | Entity page — Wikipedia | Authoritative explainer — Wikipedia, your site | Earned proof feature — Forbes, Business Insider |
| Google AI | How-to / demo video — YouTube | Demo + data posts — YouTube, LinkedIn | Best-of + earned feature — editorial roundups, trade press |
| Perplexity | Answer-first + fresh data — your site | Best-of list + comparison — your site, editorial roundups | Best-of list — editorial / affiliate roundups |
| Gemini | Answer-first guide — your site | Best-of + data analysis — editorial roundups, Medium | Best-of + earned feature — editorial roundups, trade press |
| Claude | Answer-first guide + glossary — your site | Deep comparison + how-to — your site | Decision-depth guide — your site |
Shares are directional (a long tail of citations is unclassified, so first-party is if anything understated). Read the ranking, not the absolute number.
Platform by platform
ChatGPT (~3.3 sources per answer — parametric, win via authority). It leans hardest on Wikipedia and earned press, and cites the fewest sources, so it rewards being the canonical entity more than being everywhere. Top of funnel: own a clean Wikipedia entity page and answer-first explainers on your site. Middle: authoritative explainers plus data-led features in outlets like Forbes or Business Insider. Bottom: earned proof features, plus the Reddit and review mentions it leans on to confirm a recommendation (its decision-stage recommendation rate is high, ~64%).
Google AI (~14.8 sources — retrieval-heavy, flood the slots). This is where being cited in many places pays off most, and it is uniquely heavy on YouTube, LinkedIn and Reddit. Top: how-to and demo video on YouTube plus answer-first and FAQ pages. Middle: demos and data posts (YouTube, LinkedIn) plus Reddit answer threads. Bottom: best-of and earned features in editorial roundups and trade press, reinforced by review profiles. It names a lot of brands at the top without committing, so treat awareness as a visibility play and concentrate conversion work lower down.
Perplexity (~8.1 sources — best-of-list machine, recency-driven). It favors first-party pages, trade content and "best-of" lists, and is notably recency-sensitive. In our US data it barely cites Reddit, LinkedIn or Medium (more on that tension in the methodology note). Keep your own pages provable and fresh, earn placement in third-party best-of lists, and maintain complete review profiles (Gartner, TripAdvisor, G2).
Gemini (~5.3 sources — guide and trade heavy, the most decisive). It pulls answer-first guides, best-of analysis, and trade press, and it is the most likely engine to actually recommend a brand once it surfaces one (decision-stage recommendation ~68%). Being present here converts, so prioritize trade-press inclusion and decision-stage pages.
Claude (~5.2 sources — structured-content champion, owned depth). It rewards deep, well-structured first-party content and surfaces brands the least often unprompted mid-funnel, so authority and earned depth matter most. Lead with answer-first guides, glossaries, deep comparisons and decision-depth pages on your own site, backed by earned features.
What to publish on each property
The grid tells you where. This tells you what format actually earns the citation on each property type.
| Property Type | Winning Content Type |
| Your own site (owned + operated) | Answer-first explainers (answer in the first 50–80 words), "X vs Y" comparison tables, FAQ blocks (question-as-H2), original research/data, and transparent pricing. |
| YouTube | How-to, demo and comparison video with chapters, a clean transcript, and an entity-rich description. |
| LinkedIn / Medium | Data and statistics posts plus named-executive long-form (LinkedIn); long-form analysis with original data (Medium). |
| Reddit / Quora / forums | Detailed, top-voted answer threads with authentic first-person experience, trade-offs and specific numbers. |
| Review platforms (G2, Capterra, Gartner, Trustpilot, TripAdvisor) | Be included in "best-of" roundups, plus a complete claimed profile in the correct category with recent review volume. |
| Marketplaces / OTAs (Amazon, Booking, Sephora) | Structured attributes and spec tables plus Q&A (amenities, ingredients, specs); complete listing fields. |
| Editorial & trade press | Earned, data-led features (named study, date, sample size) and inclusion in "best of" pieces. |
| Wikipedia | A notable, well-sourced entity page (earned through independent coverage, not editable as marketing). |
Three formats win at every stage and on almost every property: answer-first structure, recency, and original data you can prove.
This is a starting point: industry nuance
The grid is a cross-industry baseline. Your category will reorder it, and the differences are large enough that copying the baseline blindly will mislead you. Two clear examples from the data:
- SaaS / B2B. Review platforms jump from a minor lever to the single biggest decision-stage source (G2, Capterra, Gartner run roughly 4x their cross-industry weight at the decision stage). Wikipedia also over-indexes, because AI tends to define the category before recommending inside it. If you sell software, a complete, well-reviewed G2 profile in the right category is not optional.
- E-commerce / retail. The intuitive "get more reviews" instinct is not what the data shows. Here, Reddit and YouTube are the defining levers (community runs ~2x its baseline weight; YouTube is the #1 source mid-to-bottom), while standalone review sites stay flat. Editorial roundups (Forbes, lifestyle press) also over-index at decision.
The technical foundation under every cell
None of this works if AI cannot read or trust your pages. Underneath the whole grid sits a foundation that is the same for every platform:
- Crawl and CDN access. In our audits, basic crawlability is largely solved, but blocking, when it happens, is usually at the CDN/WAF layer (e.g., Cloudflare), not robots.txt. Check there first that AI crawlers are not blocked.
- Structured data and content trust signals. Schema coverage and trust signals (visible publish dates, author attribution) are the most common gaps. Fix these before chasing exotic tactics.
- Performance. Slow pages are a real, measurable drag.
llms.txt is worth monitoring but has no proven citation effect yet.
How to use this
- Find the platforms and funnel stages that matter most for your buyers.
- Read the top move in that cell, then the platform notes for the full set.
- Translate each move into the right format using the property table.
- Pressure-test it against your own category and your own citation data before committing budget.
FAQ
Which AI platform should I optimize for first?
Start where your buyers actually ask and where you have surface area. Google AI and Perplexity reward broad presence (they cite many sources), so they respond fastest to content and citation work. ChatGPT and Claude reward entity authority, which takes longer to build but compounds.
Why do ChatGPT and Claude cite so few sources?
They lean more on parametric/training memory and retrieve less per answer. That means you influence them less by chasing individual citations and more by being a well-known, consistently described entity across the web (Wikipedia, earned press, a coherent category story).
Does this change by industry?
Significantly. The grid is a cross-industry baseline. In SaaS, review platforms become the top decision-stage lever; in e-commerce, Reddit and YouTube outrank review sites; in travel, OTAs and trade press dominate. Always validate against your own category.
What is the single highest-leverage content type?
Answer-first, provable content. Pages that lead with the answer, include original data, and stay current get cited at far higher rates than generic blog or product pages, across platforms and stages.
Is comparison content still worth making?
Yes, but mostly for the middle of the funnel. In unbranded discovery, "X vs Y" comparisons peak at consideration and fade at the decision stage. "Best-of" inclusion is the more durable through-line.
What to do next
This grid is a map, not the territory. The fastest way to make it specific is to see which sources AI actually cites for your brand and category, then work the cells that matter.
AIVO tracks where you appear across AI platforms, explains why you are winning or losing, and turns it into prioritized actions.
Book a meeting: Grab a time with our team
---
Methodology
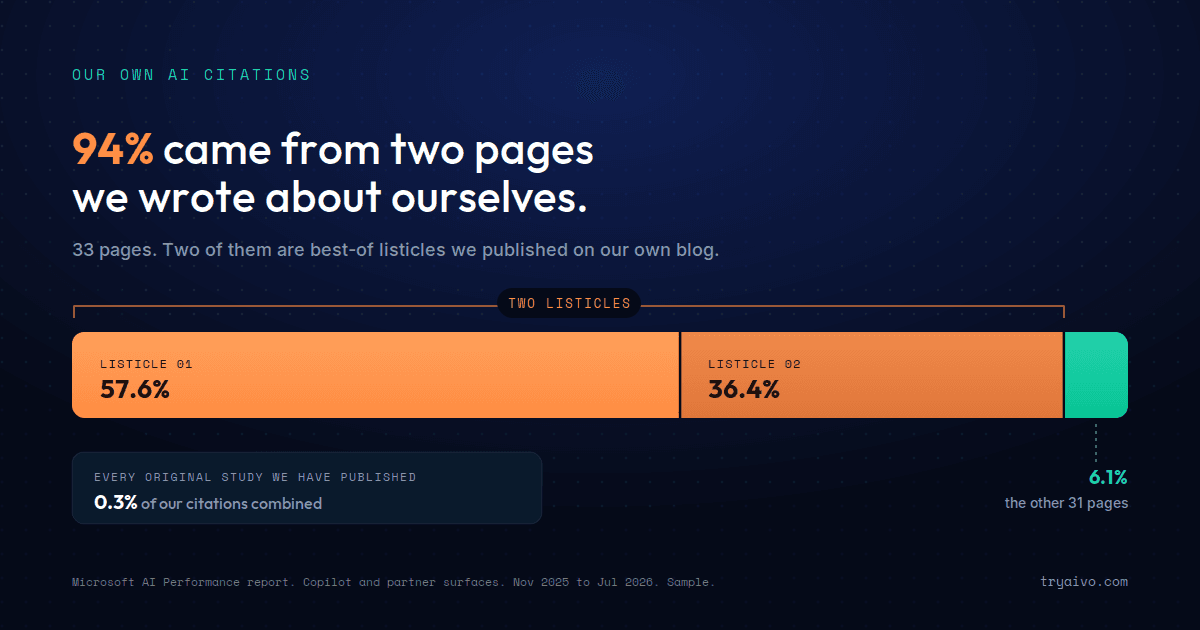
This is built on roughly 700,000 AI citations from US-English queries across ChatGPT, Google AI (Overviews and AI Mode), Perplexity, Gemini and Claude, captured between late 2025 and mid-2026, combining AIVO's client tracking and benchmark studies with external citation research. The matrix reflects the unbranded discovery view (what AI cites when someone is not already searching for a brand by name); branded/reputation queries behave differently and were analyzed separately. Citation shares are directional floors, since a long tail of sources is unclassified, and the underlying portfolio skews toward travel, retail and martech, which is why the cells use cross-industry example properties and why we call out vertical exceptions explicitly.
---
Author: Dan Muirhead is the Founder of AIVO, a strategic AI visibility consultancy powered by a proprietary intelligence platform. He helps brands in high consideration industries like hotels, cruise, e-commerce, and SaaS get found, recommended, and chosen when customers ask AI for answers, and writes about how AI search actually decides what to recommend.
Connect on LinkedIn | tryaivo.com